如何使用 TensorBoard
本文会介绍如何使用 tensorboard 进行可视化。

安装
在使用之前,可以先看看环境配置--tensorboard。
为了在 PyTorch 里愉快地使用 TensorBoard,目前建议使用 tensorboardX 写出 events.out 文件。
下面是安装命令:
pip install tensorboard tensorboardx
使用
万变不离其宗,使用方法首先应该查看文档:https://tensorboardx.readthedocs.io/en/latest/tensorboard.html
这里我以 PyTorch 训练 CRNN 模型为例,介绍如何可视化以下几个内容:
- 可视化模型结构
- 按 epoch 可视化 loss、acc
- 按 batch 可视化 loss、acc
- 可视化训练过程中 loss 比较高的样本(badcase)
使用 TensorBoard 需要做以下两件事:
- 在代码中对需要可视化的地方添加写出代码
- 打开 TensorBoard 服务
创建文件对象(writer)
import time
from tensorboardX import SummaryWriter
now = time.strftime("%Y%m%d_%H%M%S", time.localtime())
model_name = f'crnn_{now}'
print(model_name)
writer = SummaryWriter(f'logs/{model_name}')
使用上面的代码即可创建一个 writer 对象,之后我们就可以使用这个 writer 写出我们想要写出的东西。
训练一段时间以后,会在 logs 文件夹下构建以下文件结构:
logs
└── crnn_20190630_200056
├── epoch
│ ├── acc
│ │ ├── train
│ │ │ └── events.out.tfevents.1561896176.ypw-black
│ │ └── valid
│ │ └── events.out.tfevents.1561896176.ypw-black
│ ├── error_rate
│ │ ├── train
│ │ │ └── events.out.tfevents.1561896176.ypw-black
│ │ └── valid
│ │ └── events.out.tfevents.1561896176.ypw-black
│ └── loss
│ ├── train
│ │ └── events.out.tfevents.1561896176.ypw-black
│ └── valid
│ └── events.out.tfevents.1561896176.ypw-black
└── events.out.tfevents.1561896056.ypw-black
打开 TensorBoard 服务
安装了 TensorBoard 以后,直接使用下面的命令就可以打开 TensorBoard 服务:
tensorboard --logdir=logs
假设你的服务器 IP 地址是 192.168.8.100,只需要在浏览器里输入 http://192.168.8.100:6006 就可以打开 TensorBoard 面板。
可视化模型结构
模型结构的可视化非常简单,只需要构建一个输入 tensor 即可:
model = Model(n_classes, input_shape=(3, height, width))
inputs = torch.zeros((1, 3, height, width))
writer.add_graph(model, inputs)
然后你就可以在 http://192.168.8.100:6006/#graphs 里看到你的模型结构。
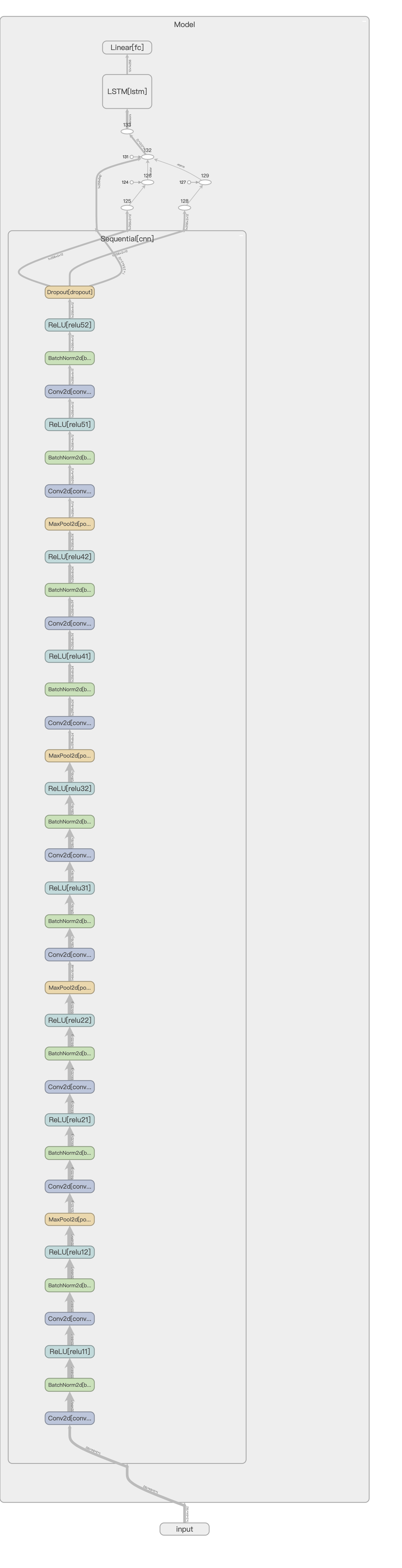
双击 Model 就可以展开它,下面是展开到合理程度的模型结构图:
记录标量(scalar)
使用 writer.add_scalar 就能轻松画出 loss 曲线,下面是经过简化的训练函数:
def train(model, optimizer, epoch, dataloader, writer):
# ...
for batch_index, (data, target) in enumerate(pbar):
# ...
output = model(data)
loss = criterion(output, target)
acc = calc_acc(target, output)
# ...
iteration = (epoch - 1) * len(dataloader) + batch_index
writer.add_scalar('train/loss', loss, iteration)
writer.add_scalar('train/acc', acc, iteration)
writer.add_scalar('train/error_rate', 1 - acc, iteration)
为了让多个图绘制在一个标签下,斜杠前面的名称需要统一,我这里以 train/ 表示,在 TensorBoard 里就可以统一绘制在 train 这个标签内,展开和合并都比较方便。
训练完以后的曲线如图:
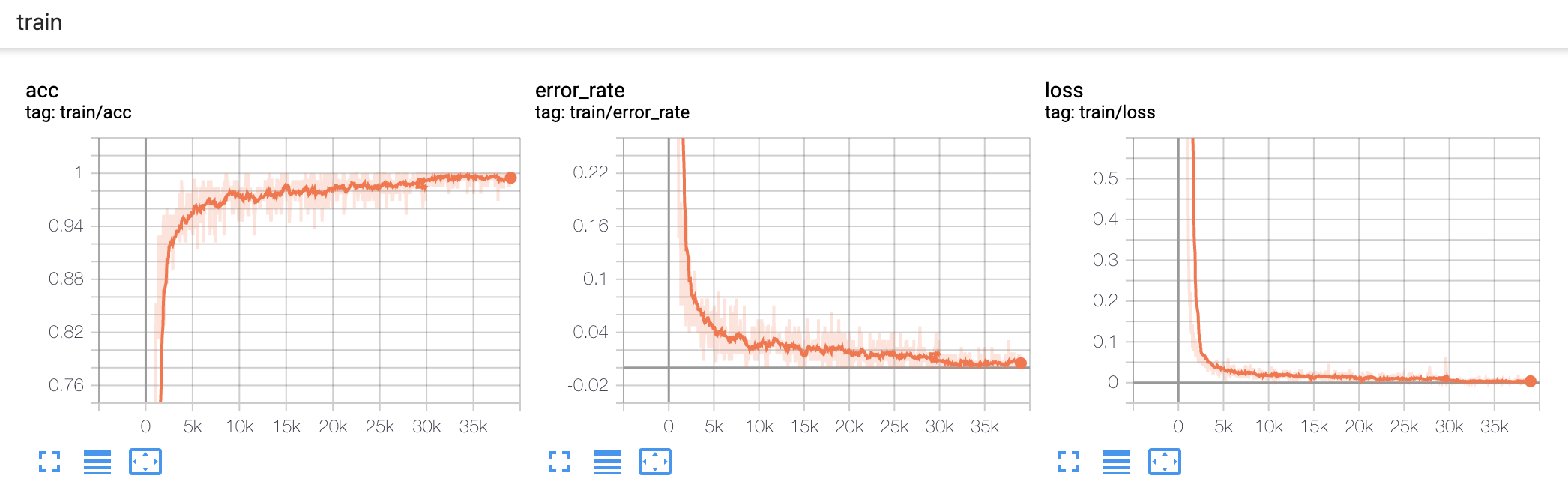
这里有一个小技巧,如果你想可视化正确率这种接近 1 的指标,最好使用错误率(1减正确率),因为当正确率非常接近 1 的时候,很难看出来趋势。使用 TensorBoard 切换到对数尺度下,就能轻松看出错误率的趋势了:
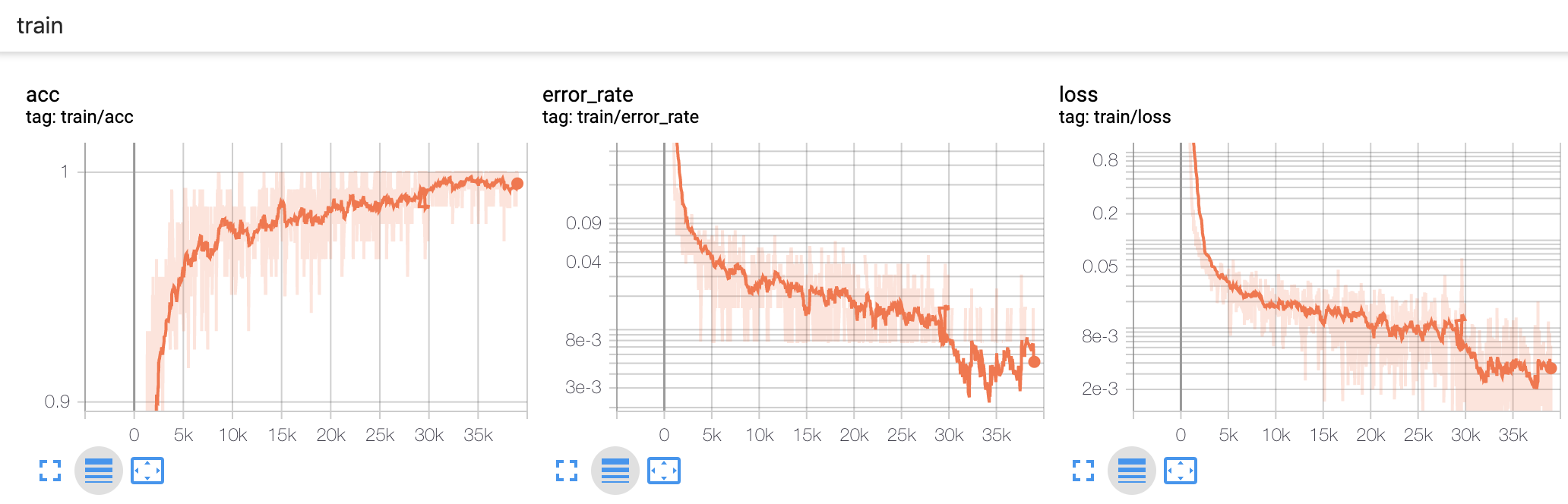
在 30k 的时候,我把学习率降低了 10倍,继续训练了 10代,如果看上面的图,只能看出来 loss 更平缓了,但是下面的对数尺度下就可以明显看出来 loss 从 8e-3 下降到了 2e-3,下降了 4 倍。
记录多个标量(scalars)
很多时候我们都需要使用训练集的 loss 和验证集的 loss 做对比,以判断模型有没有过拟合。这时候使用 writer.add_scalars 就可以将多个标量绘制在同一张图里进行对比。下面是示例代码:
for epoch in range(1, epochs + 1):
train_loss, train_acc = train(model, optimizer, epoch, train_loader, writer)
valid_loss, valid_acc = valid(model, epoch, valid_loader, writer)
writer.add_scalars('epoch/loss', {'train': train_loss, 'valid': valid_loss}, epoch)
writer.add_scalars('epoch/acc', {'train': train_acc, 'valid': valid_acc}, epoch)
writer.add_scalars('epoch/error_rate', {'train': 1 - train_acc, 'valid': 1 - valid_acc}, epoch)
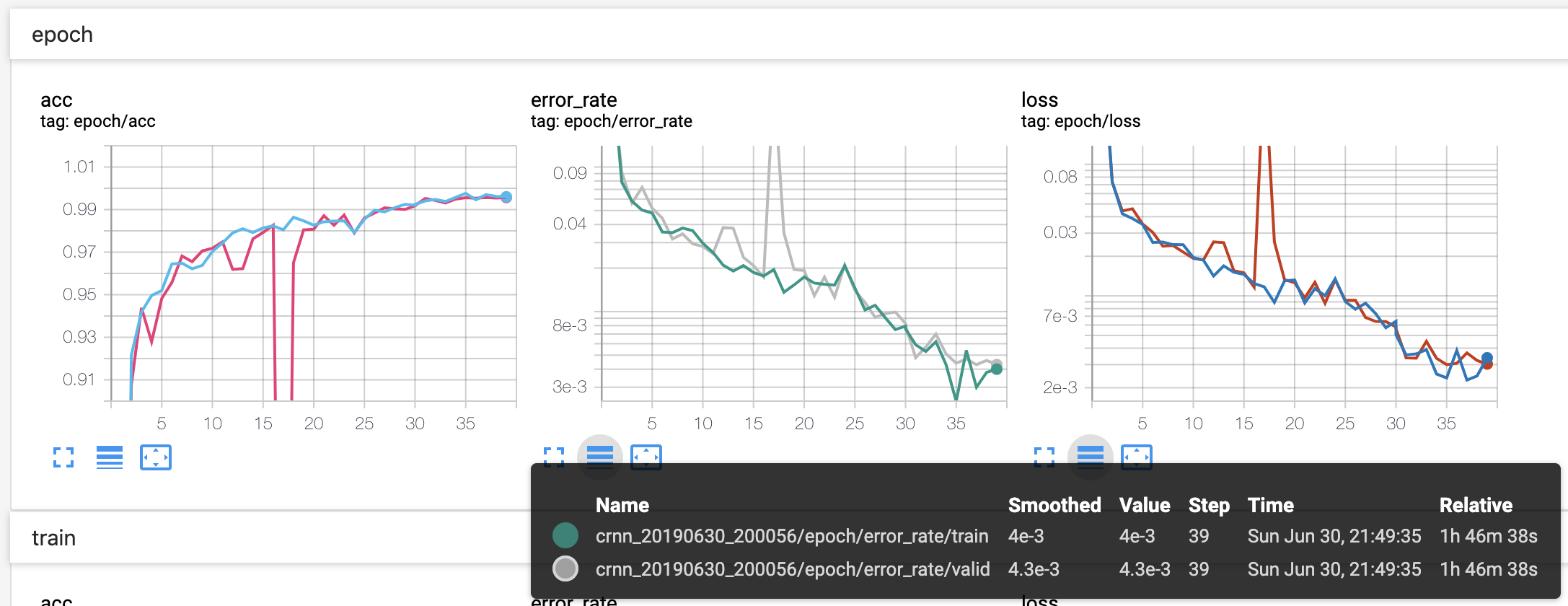
可以看到在对数尺度下,loss 和错误率还有向下走的趋势,可以继续训练。
记录图像(images)
不管是在 GAN 里,还是其他图像任务里,绘制图像都是一个很有用的功能。下面我以绘制 badcase 为例:
# draw badcase
with torch.no_grad():
output_argmax = output.detach().permute(1, 0, 2).argmax(dim=-1)
loss = F.ctc_loss(output_log_softmax, target, input_lengths, target_lengths, reduction='none')
hard_sample = np.argsort(loss.detach().cpu().numpy())[::-1]
data = data.cpu()
target = target.cpu()
nrow = 4
ncol = 4
fig = plt.figure(figsize=(12, 6))
for i, index in enumerate(hard_sample[:nrow*ncol]):
plt.subplot(ncol, nrow, i+1)
plt.axis('off')
plt.imshow(data[index].numpy().transpose(1, 2, 0))
s = f'true: {decode_target(target[index])}\npred: {decode(output_argmax[index])}'
plt.title(s)
fig.canvas.draw()
image = np.array(fig.canvas.renderer.buffer_rgba())
plt.close()
writer.add_image('train/badcase', to_tensor(image), epoch)
首先为了避免影响训练,整个代码都需要在 torch.no_grad() 下进行。然后为了获取不好识别的样本,需要重新计算 loss,并且添加 reduction='none' 以计算每个样本的 loss。
OCR 问题既需要图像,又需要文本,所以这里我们使用 matplotlib 绘制图像,然后得到矩阵比较方便。如果你只想拼接多个图像,可以使用 from torchvision.utils import make_grid 函数。
下面是训练过程中的 badcase:

可以看到大部分图像都是因为 0 和 O 识别不对,其实前面几个图我也看不出来到底是 0 还是 O。
完整代码
以上几个例子的完整代码在 https://github.com/ypwhs/captcha_break 项目中,文件名是 ctc_pytorch_tensorboard.ipynb ,该项目解决了验证码识别的问题,最终训练到了 0.9957 的准确率。
总结
使用 TensorBoard 可以监控训练过程中的 loss 趋势,及早发现问题。训练多个模型以后,还可以把多个模型的曲线放在一张图里横向对比。另外 badcase 分析也可以发现更多潜在的问题,为之后的优化寻找方向。可以说 TensorBoard 是每一个深度学习从业者的必备技能。